GSD VIS-2314: Responsive Environments: Poetics of Space (Spring 2021-22)
Students: Ibrahim Ibrahim, Kenny Kim, Jason Leo
Faculty: Allen Sayegh, Humbi Song

Project Statement:
The project endeavors to interrogate and reflect on the relationship between vision, mind, memory, and environment. Using a Signal-to-Image machine learning model, EEG brain signals are paired with their corresponding images to predict new visuals juxtaposing vision and memories. The product is a wearable device that aims to encourage a critical dialogue around human sensors, mental states, and responsive environments.
True reality is an amalgamation of vision, memories, and emotions that render our present perception of the world. However, what we see with our eyes is not what our brain always perceives – extending the hypothesis that our eyes do not tell the complete truth. While our visual sensors – eyes – are the dominant mode of environmental perception, a disturbed, stressed, or anxious mind fails to comprehend what is fully presented through the eyes.
Common Realm is an immersive electroencephalogram (EEG) based device that re-paints our vision with speculative layers seen by the mind through visualizing brain signals. This project discusses the hierarchy of memories and sensory inputs other than vision to depict the actual perception in real-time.


To corroborate the idea of investigating brainwaves to reinterpret reality, we looked at a study published in Cognitive Computation that looks at how the neural correlates human emotional judgment, stimulated by auditory, visual, or combined audio-visual stimuli. (Hiyoshi et al. 2015). This study aimed to demonstrate that EEG can be used to investigate emotional valence and discriminate various emotions.
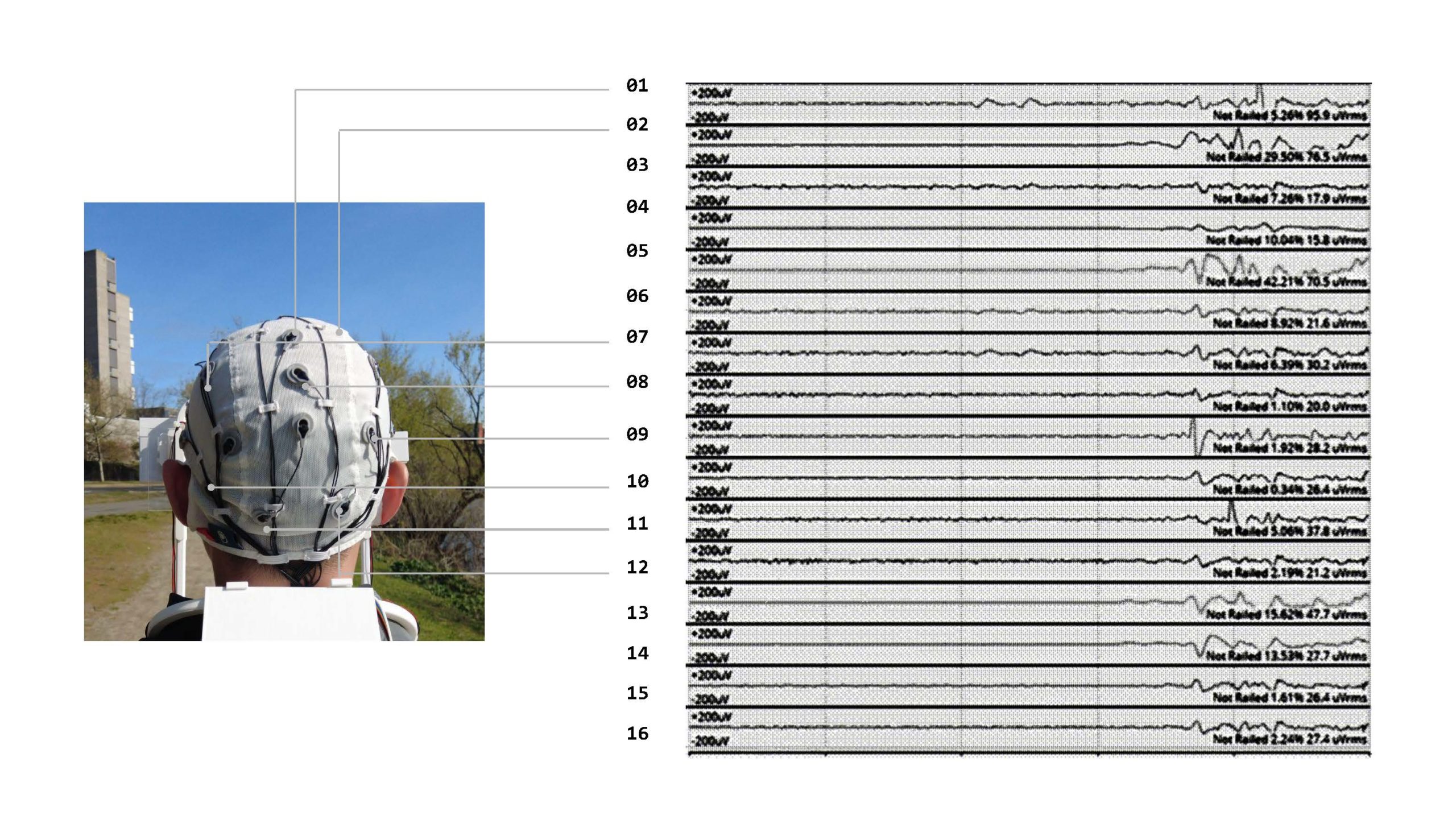
We trained a signal-to-image model using 5,000 images and labeled their corresponding brain signals for 10 seconds. Using an eye tracker embedded in the prototype device, we track the gaze during training to add hierarchical weights to certain features in the images. Once the RGB images, gaze tracking values, and brain signals are gathered, we begin the training process, followed by real-time validation testing on a segment of the Charles River. Predictions are seen to bring in new elements to the frames in real-time.
It was observed that when noises across the street, e.g., cars, were in the background, the distortion of the frames with vertical noise resembling skyscrapers was evident. At other moments when walking next to a crowd, the predicted images displayed an amalgamation of elliptical forms resembling large crowds.

